
Recently, I appeared for the Databricks Generative AI Associate Certification, and the experience was both challenging and enlightening. If you're planning to take this exam, this guide will help you navigate the unexpected twists and prepare effectively.
Here's the first surprise: the official guide mentions 45 questions in 90 minutes. However, when I logged into my exam, I was greeted with 56 questions to complete in the same 90-minute window.
Let that sink in for a moment. Instead of having approximately 2 minutes per question as I'd planned, I suddenly had just 1.2 minutes per question. Initially, I thought the extra 11 questions might be feedback-related or experimental questions that wouldn't count toward my score. I was wrong—they were all actual exam questions.
Despite this surprise, I managed to complete the exam in 64 minutes and passed successfully. Here's how I did it, and more importantly, how you can too.
The questions ranged from medium to difficult in complexity. They weren't straightforward recall questions—they required genuine understanding and application of concepts.
The exam featured two main types of questions:
Code and Implementation-Based Questions (~40%): These required you to understand actual code snippets, identify correct implementations, and recognize best practices in real-world scenarios.
Conceptual and Tricky Questions (~60%): These were designed to test your deep understanding of Gen AI concepts, not just surface-level knowledge. They often presented scenarios where multiple answers seemed correct, but only one was truly optimal.
The moment I realized there were 56 questions instead of 45, I had a choice: panic or pivot.
I chose calm.
The first and most important thing you need is to keep your mind calm and away from distractions. Time pressure can make you second-guess yourself, rush through questions, or miss critical details. Your mental state during the exam is just as important as your preparation before it.
Take a deep breath. Trust your preparation. Remember that you can't control the exam format, but you can control your response to it.
Here's the second trick I used that proved invaluable: strategic marking for review.
The Databricks exam doesn't allow you to skip questions—you can only navigate to the next question after attempting the previous one. However, you can mark questions for review and return to them later.
My approach was simple:
If I was 80% confident or more → answer and move on
If I was uncertain → mark for review and move forward
This strategy prevented me from wasting precious time on questions where I was unsure. Instead of sitting there for 3-4 minutes trying to force an answer, I maintained momentum and optimized my cognitive energy for questions where I felt confident.
By the end of my first pass through the exam, I had marked several questions for review. With time remaining, I returned to these with a fresh perspective and was able to answer them more confidently.
Now, let's talk about how I prepared for this certification—because preparation is what ultimately determines your success.
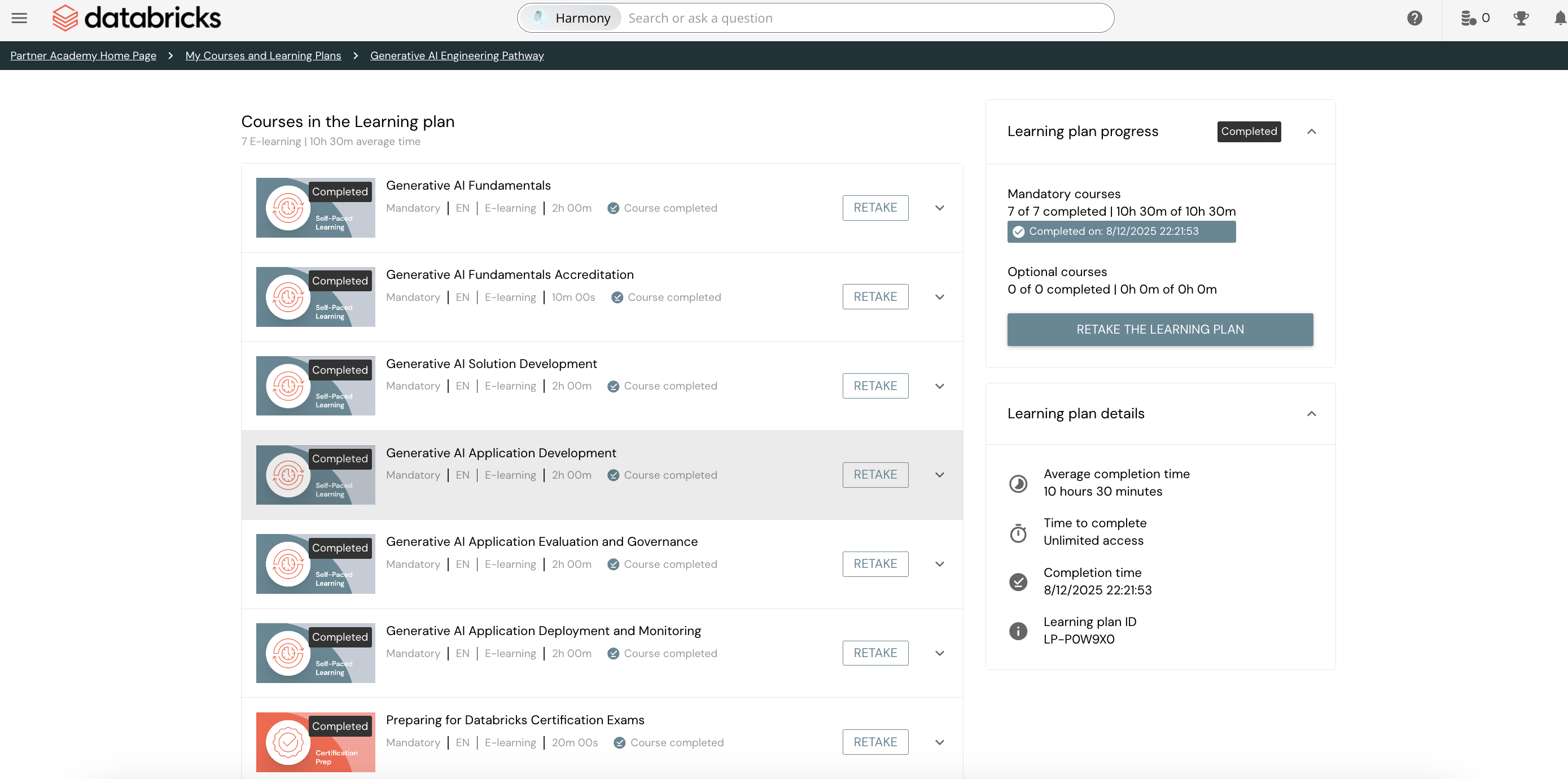
I started with all the FILT (Free Instructor-Led Training) courses provided by Databricks. Since my organization is an academy partner of Databricks, I had free access to these comprehensive courses.
These courses are excellent for building conceptual clarity. They cover:
Generative AI fundamentals
LLM architectures and capabilities
Databricks-specific implementations
Best practices for Gen AI applications
RAG (Retrieval-Augmented Generation) patterns
Model evaluation and monitoring
Don't skip these courses. They form the foundation of everything else.
After completing each video in the FILT courses, I made handwritten notes.
I know what you're thinking—handwritten notes in 2024? Isn't that outdated?
Here's my theory: I have strong muscle memory. When I write something by hand, it lasts longer in my brain. The physical act of writing engages different neural pathways than typing or just watching videos.
This technique significantly improved my retention and recall during the exam. When I encountered a question, I could visualize my notes and remember the concepts more clearly.



Video lectures make you thorough with concepts, but application-based questions make you well-versed with them. This is where practice tests become crucial.
I initially searched the internet for free practice questions. I visited several websites like ExamTopics, Dumpbase, CertLibrary, and ITExams. While these sites were helpful, they only showed a maximum of 15 questions for free, with the rest locked behind paywalls.
So I invested in two Udemy courses that proved to be game-changers:
Course 1: 3 practice test sets with 45, 46, and 47 questions each
Link: https://www.udemy.com/course/databricks-generative-ai-engineer-associate-practice-exam/
Course 2: 6 practice tests with 45 questions each
Link: https://www.udemy.com/course/databricks-certified-generative-ai-engineer-associate-practice-sets/
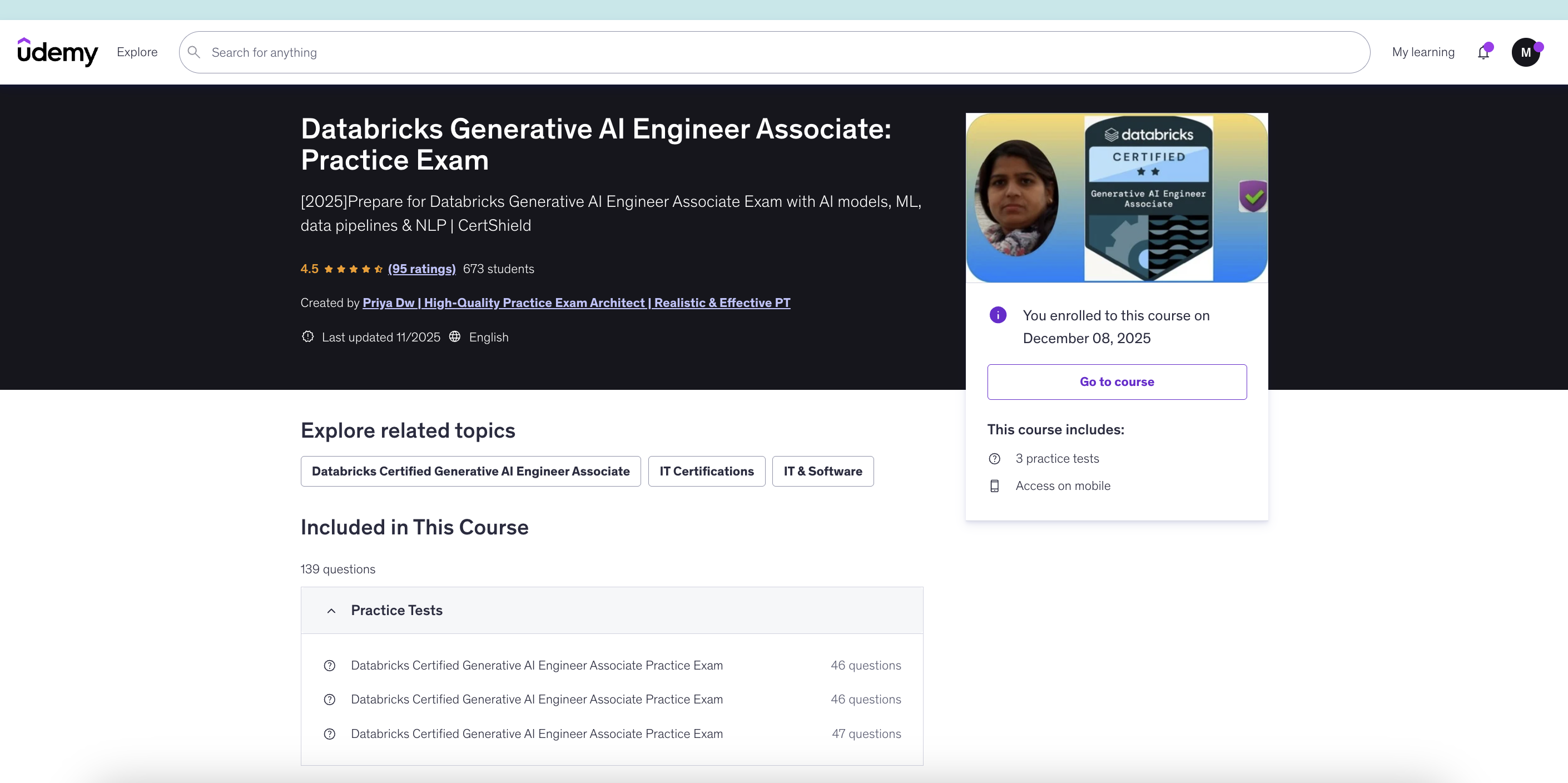
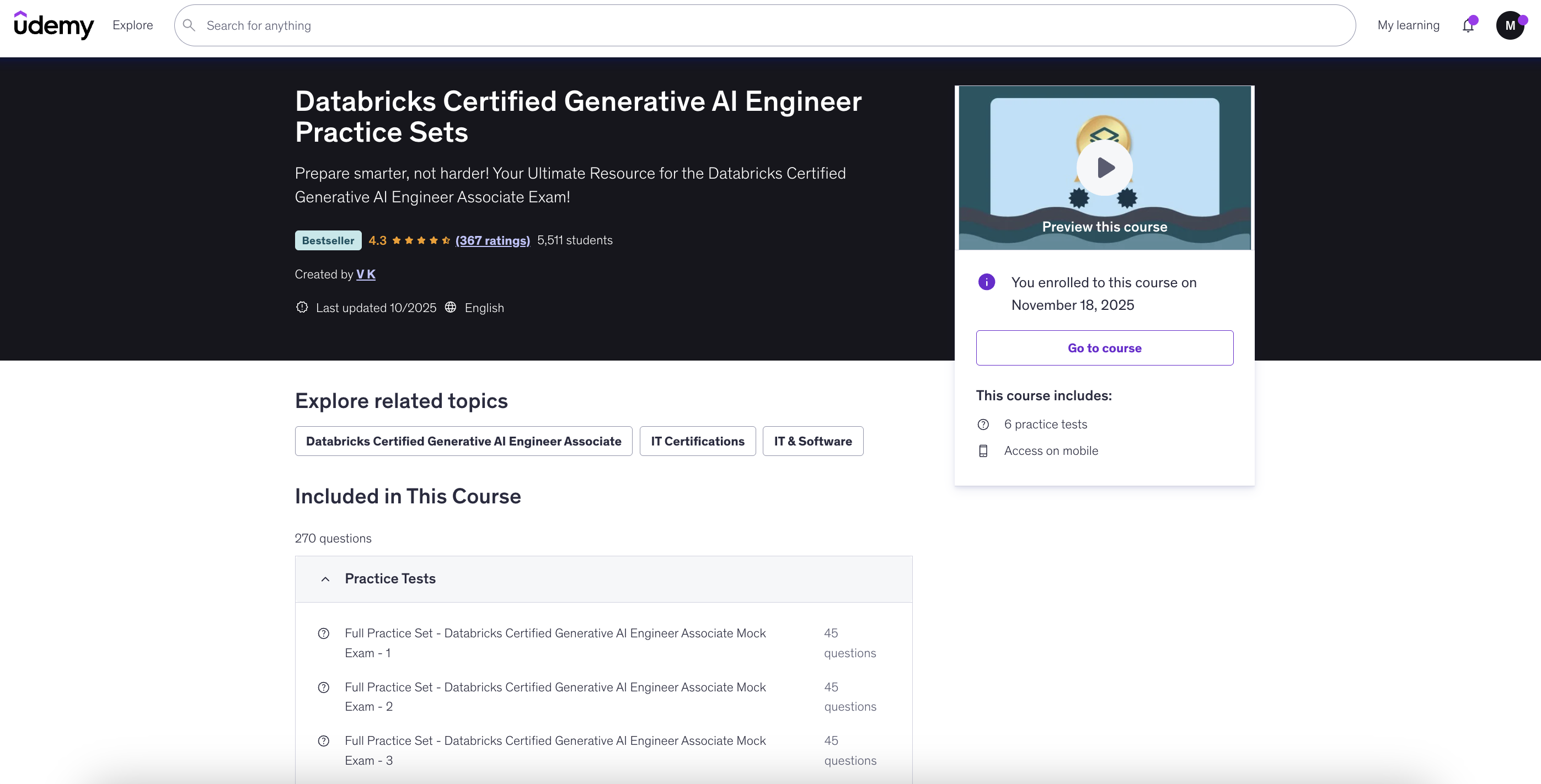
Important note: Most of the questions in my actual exam were remarkably similar to those in the first Udemy course (the one with 3 practice sets). I cannot stress this enough—practice that course thoroughly. The question patterns, difficulty level, and even specific scenarios matched very closely to the real exam.
These practice tests helped me:
Understand the exam question format
Identify my weak areas
Build time management skills
Get comfortable with code-based questions
Develop confidence through repetition
Based on my exam experience, here are the critical topics you should focus on:
Questions about where filtering should be implemented—at inference tables or during model building. Understand the performance implications and best practices for each approach.
You'll encounter questions with actual code snippets. You need to identify:
Correct syntax for prompt templates
Proper LLM model initialization
Best practices for prompt engineering in code
Variable handling and formatting
Example question type: "Which of the following code snippets correctly implements a prompt template with variables?"
Scenario-based questions about choosing the right model quality for specific use cases. For example: "If you're transferring SQL variants from one database to another, what quality characteristics should your model prioritize?"
Understanding how Gen AI models handle database migrations, SQL dialect translations, and maintaining query integrity across different database systems.
Questions on Retrieval-Augmented Generation patterns, vector databases, embedding strategies, and context window optimization.
Understanding inference tables, logging, monitoring, and debugging Gen AI applications in production.
Let me walk you through the actual exam process so you're not caught off guard.
Create an account if you don't have one
Search for "Databricks Generative AI Associate"
Book your certification exam slot
Log in 15 minutes early. This is crucial because there's a setup process:
Lock Down Browser: You'll be prompted to download and open the Lock Down Browser OEM (Online Exam Manager)

Biometric Verification: The system will require you to:
Take a photo of yourself
Take a photo of your government ID
Record audio for voice verification
Show your workspace via camera
System Check: The browser will verify your environment meets requirements
Start Exam: Once all checks are complete, you'll be prompted to begin
The entire pre-exam process takes about 10-15 minutes, which is why logging in early is essential.
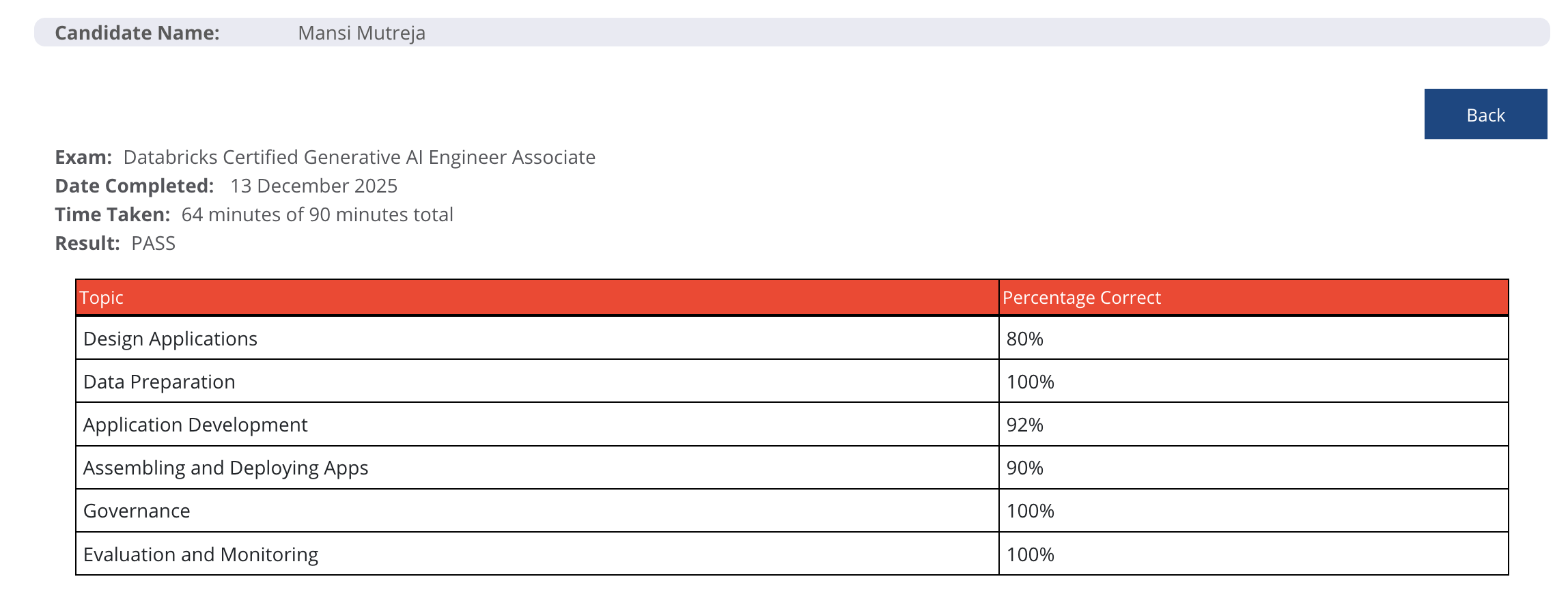
I completed the exam in 64 minutes out of the allotted 90 minutes and passed successfully.
The key to my success wasn't just knowledge—it was the combination of:
Solid conceptual foundation (FILT courses)
Active learning through handwritten notes
Extensive practice with realistic questions
Strategic time management during the exam
Mental calmness under pressure
If you're preparing for this certification, here's your step-by-step action plan:
Weeks 1-2: Foundation
Complete all Databricks FILT courses
Take handwritten notes after each video
Review notes daily
Weeks 3-4: Practice
Enroll in both Udemy practice courses
Complete all 9 practice tests
Review incorrect answers thoroughly
Identify weak areas and revisit FILT content
Week 5: Final Preparation
Retake practice tests you struggled with
Review your notes comprehensively
Practice time management (1.5 minutes per question)
Ensure your exam environment is ready
Exam Day:
Log in 15 minutes early
Complete biometric verification
Stay calm when you see the question count
Use the mark-for-review strategy
Trust your preparation
Free Resources:
Databricks FILT Courses (through academy partnership or free trials)
ExamTopics, CertLibrary, ITExams (limited free questions)
Paid Resources (Highly Recommended):
Udemy Course 1: https://www.udemy.com/course/databricks-generative-ai-engineer-associate-practice-exam/
Udemy Course 2: https://www.udemy.com/course/databricks-certified-generative-ai-engineer-associate-practice-sets/
Exam Platform:
WebAssessor: https://www.webassessor.com/wa.do?page=login
The Databricks Generative AI Associate Certification is challenging, but it's absolutely achievable with the right preparation strategy. Don't let the 56 questions intimidate you—with thorough practice and strategic time management, you'll have time to spare.
Remember: The exam tests not just your knowledge, but your ability to apply that knowledge under time pressure. Practice accordingly.
Good luck on your certification journey! If you have questions about specific topics or need clarification on any aspect of the preparation process, feel free to reach out.
Now go ace that exam!
Navigate Databricks Marketplace like a pro. Learn the 5 key criteria for choosing AI models that match your agents, LLMs, and text generation needs—without the trial-and-error.
Spark optimization isn't always complex; some tweaks have a huge impact. Inferring schemas forces Spark to scan your data twice, slowing ingestion and inflating cost. Explicit schemas avoid the extra pass and make pipelines faster and cheaper.

Cricket is no longer just a game of "gut feelings." This blog uncovers how hidden metrics like Expected Wickets and "Ghost" simulations are winning matches before the first ball. Dive into the high-stakes world where data science meets the 22 yards to redefine the sport.
I tested a simple hypothesis about image similarity - and watched it fail spectacularly when my algorithm said a "3" looks more like an "8" than another "3". The investigation revealed why pixel-by-pixel comparison is too brittle and what humans do effortlessly that machines must learn explicitly.

A practical walkthrough of how I reduced heavy batch workloads using Change Data Feed (CDF) in Databricks. This blog shows how CDF helps process only updated records, cutting compute costs and boosting pipeline efficiency.

I dropped a table in Snowflake, then queried to verify it was gone. The system said it doesn't exist, but also showed it consuming 3.57 MB. That contradiction led me down a rabbit hole of metadata delays, missing commands, and hidden costs. Here's what I discovered.
The AI industry has a security problem: data scientists aren't trained in security, ML engineers are working with black-box models, and security pros don't understand GenAI. Learn about the frameworks and tools bridging this gap—from Llama Guard to Databricks' safety features.

Why DELETE isn’t enough under GDPR, and how Time Travel can make sensitive data reappear unless VACUUM is used correctly.

This blog shares my personal journey into Snowflake Gen AI, from early confusion to hands-on clarity. It offers practical study tips, common pitfalls, and guidance to help you prepare effectively and understand Snowflake’s evolving AI capabilities.

Started scrolling Instagram at 2 AM. Saw Cloudflare memes. Fell down a 4-hour research rabbit hole. Discovered that AND database = 'default' could have prevented the whole thing. My sleep schedule is ruined but at least I understand distributed systems now.

Discover the top 10 data pipeline tools every data engineer should know in 2025. From Airflow to Fivetran, learn how each tool powers modern data workflows, supports real-time analytics, and scales across cloud ecosystems.

Confused between a data lake, data warehouse, and data mart? Discover key differences, real-world use cases, and when to use each architecture. Learn how to build a modern, layered data strategy for scalability, governance, and business insights.

Explore what syntax means in the world of data and AI—from SQL and Python to JSON and APIs. Learn why syntax matters, common errors, real-world examples, and essential best practices for data engineers, analysts, and AI developers in 2025.

Discover how AWS Data Pipeline helps automate data movement and transformation across AWS services like S3, Redshift, and EMR. Learn its key features, benefits, limitations, and how it compares to modern tools like AWS Glue and MWAA.

Learn how to build scalable and secure data pipeline architectures in 2024 with best practices, modern tools, and intelligent design. Explore key pillars like scalability, security, observability, and metadata tracking to create efficient and future-proof data workflows.

Explore the key differences between ETL and ELT data integration methods in this comprehensive guide. Learn when to choose each approach, their use cases, and how to implement them for efficient data pipelines, real-time analytics, and scalable solutions.
Learn the essential role of ETL (Extract, Transform, Load) in data engineering. Understand the three phases of ETL, its benefits, and how to implement effective ETL pipelines using modern tools and strategies for better decision-making, scalability, and data quality.

Discover why data orchestration and analysis are essential for modern data systems. Learn how automation tools streamline data workflows, boost insights, and scale with your business

Learn what a data ingestion pipeline is, why it's vital for modern analytics, and how to design scalable, real-time pipelines to power your data systems effectively.

Discover the top 15 data warehouse tools for scalable data management in 2024. Learn how to choose the right platform for analytics, performance, and cost-efficiency.

Confused between a data mart and a data warehouse? Learn the key differences, use cases, and how to choose the right data architecture for your business. Explore best practices, real-world examples, and expert insights from Enqurious.

Discover the top 10 predictive analytics tools to know in 2025—from SAS and Google Vertex AI to RapidMiner and H2O.ai. Learn why predictive analytics is essential for modern businesses and how to choose the right tool for your data strategy.

Explore the key differences between descriptive and predictive analytics, and learn how both can drive smarter decision-making. Discover how these analytics complement each other to enhance business strategies and improve outcomes in 2025 and beyond.

Explore the key differences between predictive and prescriptive analytics, and learn how both can drive smarter decisions, enhance agility, and improve business outcomes. Discover real-world applications and why mastering both analytics approaches is essential for success in 2025 and beyond.

Compare PostgreSQL vs SQL Server in this comprehensive guide. Learn the key differences, strengths, and use cases to help you choose the right database for your business needs, from cost to performance and security.

Learn what Power BI is and how it works in this beginner's guide. Discover its key features, components, benefits, and real-world applications, and how it empowers businesses to make data-driven decisions.

Explore what a Business Intelligence Engineer does—from building data pipelines to crafting dashboards. Learn key responsibilities, tools, and why this role is vital in a data-driven organization.

Discover why data lineage is essential in today’s complex data ecosystems. Learn how it boosts trust, compliance, and decision-making — and how Enqurious helps you trace, govern, and optimize your data journeys.

Learn what a data mart is, its types, and key benefits. Discover how data marts empower departments with faster, targeted data access for improved decision-making, and how they differ from data warehouses and data lakes.

Master data strategy: Understand data mart vs data warehouse key differences, benefits, and use cases in business intelligence. Enqurious boosts your Data+AI team's potential with data-driven upskilling.

Learn what Azure Data Factory (ADF) is, how it works, and why it’s essential for modern data integration, AI, and analytics. This complete guide covers ADF’s features, real-world use cases, and how it empowers businesses to streamline data pipelines. Start your journey with Azure Data Factory today!

Discover the key differences between SQL and MySQL in this comprehensive guide. Learn about their purpose, usage, compatibility, and how they work together to manage data. Start your journey with SQL and MySQL today with expert-led guidance from Enqurious!

Learn Power BI from scratch in 2025 with this step-by-step guide. Explore resources, tips, and common mistakes to avoid as you master data visualization, DAX, and dashboard creation. Start your learning journey today with Enqurious and gain hands-on training from experts!

AI tools like ChatGPT are transforming clinical data management by automating data entry, enabling natural language queries, detecting errors, and simplifying regulatory compliance. Learn how AI is enhancing efficiency, accuracy, and security in healthcare data handling.

Big Data refers to large, complex data sets generated at high speed from various sources. It plays a crucial role in business, healthcare, finance, education, and more, enabling better decision-making, predictive analytics, and innovation.

Discover the power of prompt engineering and how it enhances AI interactions. Learn the key principles, real-world use cases, and best practices for crafting effective prompts to get accurate, creative, and tailored results from AI tools like ChatGPT, Google Gemini, and Claude.

Learn what a Logical Data Model (LDM) is, its key components, and why it’s essential for effective database design. Explore how an LDM helps businesses align data needs with IT implementation, reducing errors and improving scalability.

Discover the power of a Canonical Data Model (CDM) for businesses facing complex data integration challenges. Learn how CDM simplifies communication between systems, improves data consistency, reduces development costs, and enhances scalability for better decision-making.

Discover the 10 essential benefits of Engineering Data Management (EDM) and how it helps businesses streamline workflows, improve collaboration, ensure security, and make smarter decisions with technical data.

Explore how vibe coding is transforming programming by blending creativity, collaboration, and technology to create a more enjoyable, productive, and human-centered coding experience.

Learn how Azure Databricks empowers data engineers to build optimized, scalable, and reliable data pipelines with features like Delta Lake, auto-scaling, automation, and seamless collaboration.

Explore the top 10 data science trends to watch out for in 2025. From generative AI to automated machine learning, discover how these advancements are shaping the future of data science and transforming industries worldwide.

Discover the key differences between data scientists and data engineers, their roles, responsibilities, and tools. Learn how Enqurious helps you build skills in both fields with hands-on, industry-relevant learning.

Discover the 9 essential steps to effective engineering data management. Learn how to streamline workflows, improve collaboration, and ensure data integrity across engineering teams.

Azure Databricks is a cloud-based data analytics platform that combines the power of Apache Spark with the scalability, security, and ease of use offered by Microsoft Azure. It provides a unified workspace where data engineers, data scientists, analysts, and business users can collaborate.

In today's data-driven world, knowing how to make sense of information is a crucial skill. We’re surrounded by test scores, app usage stats, survey responses, and sales figures — and all this raw data on its own isn’t helpful.

In this blog, we will discuss some of the fundamental differences between AI inference vs. training—one that is, by design, artificially intelligent.

This guide provides a clear, actionable roadmap to help you avoid common pitfalls and successfully earn your SnowPro Core Certification, whether you’re making a career pivot or leveling up in your current role.

"Ever had one of those days when you’re standing in line at a store, waiting for a sales assistant to help you find a product?" In this blog we will get to know about -What is RAG, different types of RAG Architectures and pros and cons for each RAG.

Discover how Databricks and Snowflake together empower businesses by uniting big data, AI, and analytics excellence

How do major retailers like Walmart handle thousands of customer queries in real time without breaking a sweat? From answering questions instantly to providing personalized shopping recommendations, conversational AI reshapes how retailers interact with their customers.